
Understanding Cluster for Spark
Get the most out of your cluster using Spark configurations
When we get hardware for our Spark project, we always wonder, what should be the ideal configuration while submitting the job, as per the hardware provided. To have better performance, there are two most important factor, we should consider.
CPU/Cores
Memory
Let's discuss a usecase and find out what should be the value of
No. of executor for each node
Total No. of executor instances i.e. --num-executors or spark.executor.instances
No. of Cores for each executor i.e. --executor-cores or spark.executor.cores
Memory for each executor i.e. --executor-memory or spark.executor.memory - default is 1g
Let's visualize it ...
Relation between Node, executor, Core, Task
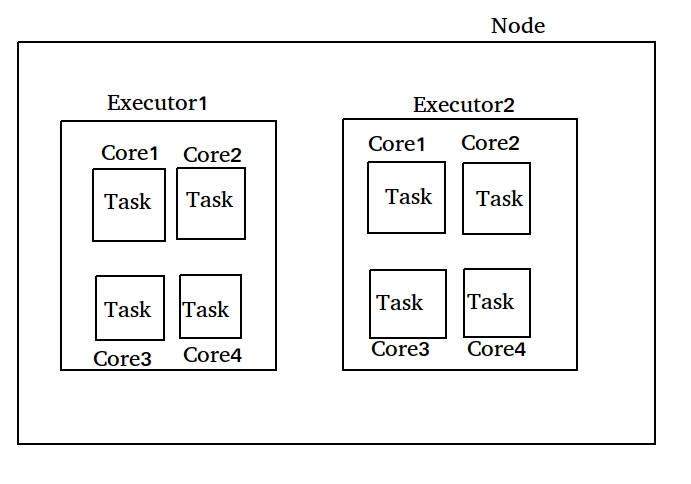
Memory
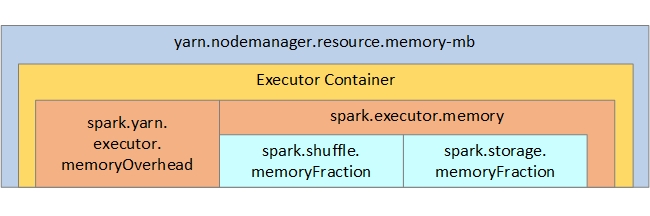
Now, let's assume , we got hardware of below configuration
No. of nodes = 6
No. of cores in each Node = 16 Core
RAM in each Node = 64 GB

Now let's calculate what should be the ideal configuration for your spark job
Point to remember:
YARN Application master (AM) needs one executor
Keep 1 core for daemon process in each node
Ideally, No. of core per executor should be 5
From each node, 1 GB RAM will be dedicated for system related process
So, from above,
Applying rule 3
There should be 5 cores per executor i.e. --executor-cores or spark.executor.cores = 5 (Ans. of 3)
Let's apply rule 2 :
Cluster has (16-1)x6 = 90 cores
That means, No. of executor in the cluster = 90/5 = 18
Applying rule 1 :
Among 18, one executor for AM i.e. Actual No. of executors = 18 - 1 = 17
--num-executors or spark.executor.instances = 17 (Ans. of 2)
Then, each node can have 17/6 ~= 3 executors (Ans. of 1)

Let's calculate memory
Among 64GB RAM from each node, 1 GB RAM will be for system related tasks
So, left out RAM per each node = 64-1 = 63 GB
There are 3 executor per each node, So memory per executor = 63/3 = 21 GB RAM
But, there will be 7% overhead, hence, the memory left = 21 x (1 - 0.7) =~= 19GB RAM
--executor-memory or spark.executor.memory = 19GB (Ans. of 4)
This is the configuration if you run one job in your cluster. But in practical scenario, you need to run multiple job. So accordingly divide among no. of jobs you are planning to run at a time.
This article gives you overal idea to calculate the resource available in your cluster.
Play accordingly.
Hope it helps :)
Last updated
Was this helpful?